
Back in the olden days, there used to be a site called the Front for the Mathematics arXiv. It lasted from the 90s until a few years ago, and had a nicer website than the arXiv itself started out with. It also served search results in a much nicer way than the arXiv, even as the latter improved over time. As a result, some people had a habit of using it to look up papers, and, as it happened, supply links to said papers on MathOverflow.
When the Front finally packed up shop, there were about 900 links to it. Stackexchange, the company, has ways of mass-editing urls without causing chaos (i.e. bumping all edited questions), but this has to be done algorithmically, of course…and the arXiv Front identifiers were not always identical to the arXiv ones, and hence the paper part of the url was not the same. Woah woah, I hear you say: what do you mean? That the Front was rolling its own article IDs? Yep.
The reason for this is that the arXiv didn’t launch into the world fully formed: it started out with physics, and there were sorta-parallel, not-quite-independent arXiv-like repos for various subjects in maths. If you go back in the ‘what’s new’ postings to 1994–1996, you can see things like the “q-alg archive” appear (now math.QA), in this case due to people not knowing where to put things like quantum knot invariants, and it ending up in hep-th. There were names for topics like dg-ga and so on. By mid-2007, all the arXiv identifiers across all subjects were unified, but before that you had area-specific prefixes (eg math/0102003, cond-mat/0102003 or hep-th/0102003), but before that, you had an even more granular system just for mathematics, similar to how physics was split up. Pre-1998 you had alg-geom, dg-ga, funct-an, and q-alg, and also math-ph. There was a parallel system at one point, allowing for eg math.DG/0307245 and math/0307245 to point to the same paper. There were also more actual independent preprint repos, like the the Hopf archive, the K-Theory archive, and the Banach archive. These slowly got absorbed into the arXiv itself. The upshot is, the arXiv Front had a slightly more systematic referencing system, as far as I can tell, while still recognising the actual arXiv identifiers. It would assign an ID that was just a number to a paper, since it was intended to only covers mathematics, at least to start, and so the hassle of having parallel identifiers in different topics wouldn’t raise its head.
However, the fun part is that when the issue was raised last year on meta.MO on 25th August, after nearly 18 months of broken links, the different types of IDs was known and pointed out, but there was no extant documentation on how the Front created its own IDs! This point was compounded by situations where people on MO would write “…and see also this paper.” with no additional information and the only context was that it was presumably relevant to the question. Sometimes an answer from 2009 (before current social norms were firmed up) would be “This is answered in this paper“, and that’s it. The only thing we knew for sure was the year and month of the paper, and maybe the subject it was in (but not eg the arXiv subject area). If the Stackexchange gurus went ahead and did a blanket search-and-replace for the arXiv Front domain and replace it with arXiv.org, the situation would be even worse, since we wouldn’t have the original link to work with, and the new link might point to something it shouldn’t.
Martin Sleziak, an indefatigable MO/meta.MO editor, wrote an epic answer full of targeted search queries looking for papers in the various date ranges and with what should be all the different ID formats, reporting the numbers of each, and classified them into categories depending on how automated the editing might need to be. He also found some of the needed translation, and eventually I found an old help page on the Wayback Machine that spelled out the actual encoding, in glorious late 90s web design:
Until March 2000, the Front renumbered articles in the old mathematical archives alg-geom, funct-an, dg-ga, and q-alg as math archive articles. To avoid duplicate numbers, the system added 50 to each funct-an number, 100 for dg-ga, and 140 for q-alg. Since this system was never adopted at the arXiv, it has for now been scrapped. If you use cite or link to any math articles math.XX/yymmnnn, where the year yy is 97 or prior and the number nnn is less than 200, you should convert back to the original numbers as stamped on the articles themselves.
That was five months in to the project of slowly editing questions and answers the old-fashioned way, by hand, replacing broken URLs we knew how to deal with, but which were still in the pre-2007 era of ID weirdness. They couldn’t be done too many at a time, and someone did complain I was editing too much, because it pushed new questions further down the front page, and off it entirely quicker than usual.
Further, since leaving a link direct to a pdf, say, and merely saying “this paper”, means the person reading the question needs to open up a pdf to know what the paper is (not helpful on mobile!), I took it on myself to include actual bibliographic information in fixing the link from the Front, to the arXiv proper. Knowing you are being referred to a 2002 arXiv paper of Perelman means you can recognise it instantly. Even better, I tried to include a journal reference and even a doi link, earlier on in the project, when I was fresh and keen (sometimes people would also link to unstable publisher urls, and there are still problems with these, especially those pointing to opaque springerlink URLs which no longer exist!). This is one way of future-proofing the system, and making it more information-rich for both human and machine readers. I have a suspicion that the arXiv is now implementing a doi system for its articles, for the day when arxiv.org may not be the address we visit when looking for papers.
Another problem is that people also supplied links in comments, and comments cannot be edited except by a mod. So our solution was to give a reply comment pointing out the fact the Front link was broken, and supply the working arXiv.org link. When particularly motivated, I included the paper title and sometimes even more bibliographic info. Asaf Karagila whacked a few of these with his mod powers, editing them directly, but leaving the mods to fix all of these is not an option.
After slow work by user ‘Glorfindel‘ (a mod on the big meta.SE), who wrote a script to do slow edits every couple of days, Martin, and myself, on the 29th March this year, I edited the last outstanding link to a pre-April 2007 Front link—every broken custom arXiv Front url was now working in questions and answers, and every comment with such a link had a reply pointing out what it should be pointing to. For good measure, I went ahead over the next day or so and edited the rest of the few links to papers in 2007, so that any replacement code can deal with a clean date division where it needs to be active. Between 20th September 2021 and 30th March, it turns out I fixed a bit over 200 broken links, and responded to about 100 comments with new, working links. The graph showing all removals of “front.math.ucdavis.edu” back through the lifetime of MO on the SE2.0 platform is quite dramatic:

Now that all the manual edits are done, the Stackexchange Community Mods (these are SE employees, not just elected users) are looking at the situation again and how the 2008–2019 links can be automatically edited by a script. Watch this space…
So what is the takeaway, if any? Don’t leave links to papers on MathOverflow without some minimum identifying information! The problem is similar for links to papers on people’s personal websites, that have evaporated after a decade, and as noted above, publisher urls instead of doi links. Without a title and at least one author, someone has to spend the time tracking this stuff down. If the MO user who posted the link has moved on, sometimes there is very little that can be done. By spending the time even just copying the title of the paper, an MO user is helping potentially many people downstream, and certainly saving the time of someone like me, who enjoys such a detective task but would prefer not to need to do it!
 , or rather
, or rather  ). I abandoned this paper very close to being finished, as I started working on what would eventually become my thesis, and also because I was going around in circles a bit, and not sure it was worth releasing. Maybe the result wasn’t that stellar, but I think it’s not been done in this way before (and it is much easier to understand than comparable results in the literature). The paper (with the above title) is now on the arXiv as
). I abandoned this paper very close to being finished, as I started working on what would eventually become my thesis, and also because I was going around in circles a bit, and not sure it was worth releasing. Maybe the result wasn’t that stellar, but I think it’s not been done in this way before (and it is much easier to understand than comparable results in the literature). The paper (with the above title) is now on the arXiv as 
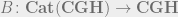 extends along the Yoneda embedding to define a “classifying space” 2-functor from a suitable 2-category of topological stacks of categories to the 2-category of spaces, maps and homotopy classes of homotopies. This improves on contemporaneous work of
extends along the Yoneda embedding to define a “classifying space” 2-functor from a suitable 2-category of topological stacks of categories to the 2-category of spaces, maps and homotopy classes of homotopies. This improves on contemporaneous work of 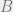 is also a somewhat orthogonal generalisation of Ebert’s work, since Noohi works with topological stacks under the open cover topology, and on all spaces, whereas my setup works with the numerable topology, and compactly-generated Hausdorff spaces. It does, however, allow for the full 2-category including non-invertible 2-arrows, which is not covered by the usual familiar
is also a somewhat orthogonal generalisation of Ebert’s work, since Noohi works with topological stacks under the open cover topology, and on all spaces, whereas my setup works with the numerable topology, and compactly-generated Hausdorff spaces. It does, however, allow for the full 2-category including non-invertible 2-arrows, which is not covered by the usual familiar 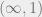 -setup.
-setup. goes back to work in the 1980s, particularly of Killingback, starting as an analogue of a spin structure on the loop space
goes back to work in the 1980s, particularly of Killingback, starting as an analogue of a spin structure on the loop space 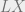 . In the decades since, increasingly refined versions of string structures have been defined. Ultimately, one wants to have a full-fledged String 2-bundle with connection, a structure from higher geometry, which combines differential geometry and category-theoretic structures. A half-way step, due to Waldorf, is known as a “geometric string structure”. Giving examples of such structures, despite existence being know, has been an outstanding problem for some time. In this talk, I will describe joint work with Raymond Vozzo on our framework for working with the structure that obstruct the existence of a geometric string structure, which is a 2-gerbe with connection, as well as give a general construction of geometric string structures on reductive homogeneous spaces.
. In the decades since, increasingly refined versions of string structures have been defined. Ultimately, one wants to have a full-fledged String 2-bundle with connection, a structure from higher geometry, which combines differential geometry and category-theoretic structures. A half-way step, due to Waldorf, is known as a “geometric string structure”. Giving examples of such structures, despite existence being know, has been an outstanding problem for some time. In this talk, I will describe joint work with Raymond Vozzo on our framework for working with the structure that obstruct the existence of a geometric string structure, which is a 2-gerbe with connection, as well as give a general construction of geometric string structures on reductive homogeneous spaces.